Introdução
Os comandos GNU e Unix constituem a espinha dorsal da experiência de linha de comando no ecossistema Linux. Essas ferramentas versáteis e poderosas capacitam os usuários a interagir com o sistema operacional de maneira ágil e eficiente, permitindo a execução de uma variedade de tarefas, desde navegar pelo sistema de arquivos até gerenciar arquivos, buscar informações e compactar dados.
Neste guia, embarcaremos em uma jornada de aprendizado para dominar esses comandos essenciais, explorando conceitos fundamentais e exemplos práticos que o capacitarão a se tornar um profissional de Tecnologia da Informação mais habilidoso e confiante, confira.
1. PARTIÇÕES E Sistema de Arquivos no Linux
As partições desempenham um papel crucial na organização e no gerenciamento de espaço em disco no Linux e em outros sistemas operacionais. Elas dividem um disco rígido ou outro dispositivo de armazenamento em segmentos separados, permitindo a separação de diferentes tipos de dados, sistemas operacionais ou configurações. Aqui está uma descrição das partições no Linux e sua importância:
O que são Partições no Linux?
Uma partição é uma seção lógica de um disco rígido ou outro dispositivo de armazenamento que é tratada pelo sistema operacional como uma unidade de armazenamento independente. As partições permitem que você organize e isole dados de maneira eficiente, fornecendo uma maneira de criar limites distintos para diferentes tipos de informações. Cada partição é tratada como se fosse um dispositivo de armazenamento separado, com seu próprio sistema de arquivos e diretórios.
Importância das Partições no Linux
1. Separação de Dados: As partições permitem isolar diferentes tipos de dados, como sistema operacional, arquivos de usuário, programas e dados temporários. Isso melhora a organização, facilita o backup e ajuda a evitar que uma falha afete todas as informações no disco.
2. Segurança e Isolamento: Ao separar diferentes tipos de dados em partições distintas, você pode melhorar a segurança e o isolamento. Se um sistema for comprometido, os danos podem ser limitados à partição afetada, enquanto as outras permanecem intactas.
3. Compatibilidade com Múltiplos Sistemas: Partições permitem que você execute diferentes sistemas operacionais em um único disco. Isso é útil para dual boot (inicialização dupla), permitindo que você escolha qual sistema operacional inicializar.
4. Gerenciamento de Espaço: Partições ajudam a melhorar o gerenciamento de espaço em disco. Você pode alocar espaço separado para diretórios específicos, como /home ou /var, evitando que esses diretórios fiquem sem espaço e afetem o funcionamento do sistema.
Tipos de Partições
1. Partição Primária: A partição primária é a principal unidade de armazenamento no disco. Um disco pode ter até quatro partições primárias ou três partições primárias e uma partição estendida.
2. Partição Estendida: Uma partição estendida é um tipo especial de partição que pode conter partições lógicas dentro dela. Isso permite criar mais de quatro partições em um disco.
3. Partição Lógica: As partições lógicas residem dentro de uma partição estendida e são usadas para criar unidades de armazenamento adicionais. O Linux pode montar partições lógicas da mesma maneira que as primárias.
Montagem de Partições
As partições devem ser montadas em um diretório vazio no sistema de arquivos para serem acessadas. O processo de montagem torna o conteúdo da partição acessível em uma determinada pasta (ponto de montagem).
No geral, o uso adequado de partições no Linux é crucial para a organização eficiente de dados, o gerenciamento de espaço em disco e a segurança. Entender os diferentes tipos de partições e como montá-las corretamente é uma habilidade fundamental para administradores de sistemas e usuários avançados do Linux.
Padrões de Partição MBR e GPT no Linux
Quando se trata de particionamento de discos no Linux, dois padrões amplamente utilizados são o MBR (Master Boot Record) e o GPT (GUID Partition Table). Cada um desses padrões tem suas próprias características e implicações, afetando como as partições são organizadas e gerenciadas em um sistema. Vamos explorar esses dois padrões em detalhes:
MBR (Master Boot Record)
O MBR é um padrão mais antigo para particionamento de discos e foi amplamente utilizado por muitos anos. Ele está gravado no primeiro setor (o setor de inicialização) do disco e contém informações vitais para inicialização do sistema e identificação das partições. No entanto, o MBR possui algumas limitações:
1. Limite de Partições: O MBR suporta no máximo quatro partições primárias ou três partições primárias e uma partição estendida. Essa limitação pode ser restritiva em sistemas que exigem mais partições.
2. Tamanho de Disco Limitado: Devido às limitações de endereçamento, o MBR não é adequado para discos maiores que 2 terabytes (TB), pois não consegue endereçar espaços além desse tamanho.
3. Problemas de Segurança: O MBR não possui recursos avançados de segurança, o que torna o sistema mais suscetível a ameaças como ataques de boot.
GPT (GUID Partition Table)
O GPT é um padrão mais recente e robusto para particionamento de discos. Ele supera muitas das limitações do MBR e é amplamente adotado em sistemas modernos. O GPT utiliza uma tabela de partições mais estruturada e flexível, permitindo mais partições e tamanhos de disco maiores. Algumas das vantagens do GPT incluem:
1. Suporte a Discos Grandes: O GPT pode suportar discos com tamanhos superiores a 2 TB, tornando-o ideal para sistemas que usam discos de alta capacidade.
2. Partições Ilimitadas: O GPT suporta um número praticamente ilimitado de partições. Isso é possível graças à estrutura da tabela de partições.
3. Maior Resiliência: O GPT armazena cópias redundantes de sua tabela de partições, tornando o sistema mais resistente a falhas e danos.
4. Identificação Única (GUID): Cada partição no GPT possui um identificador único chamado GUID (Globally Unique Identifier), o que evita conflitos de identificação entre partições.
5. Segurança Aprimorada: O GPT suporta recursos de segurança, como verificação de integridade e criptografia.
Escolhendo entre MBR e GPT
A escolha entre MBR e GPT dependerá das necessidades específicas do seu sistema. Para discos menores e sistemas mais antigos, o MBR pode ser uma opção viável. No entanto, para discos grandes, sistemas modernos e onde a segurança é uma preocupação, o GPT é altamente recomendado.
Ao criar partições no Linux, você deve selecionar o padrão apropriado ao iniciar o processo de particionamento. O GPT é mais versátil e é a escolha preferencial para a maioria dos cenários atuais, oferecendo maior flexibilidade e recursos avançados de gerenciamento de partições.
2. SISTEMA DE ARQUIVOS NO LINUX
O Linux, um sistema operacional amplamente utilizado, é construído sobre um robusto sistema de arquivos. Esse sistema hierárquico organiza todos os dados em uma estrutura de diretórios interconectados. Imagine cada diretório como uma gaveta em um arquivo enorme, e cada arquivo como um documento importante dentro dela. A partir da raiz, representada pelo símbolo “/”, você navega por diferentes caminhos para encontrar e gerenciar seus arquivos.
Existem vários sistemas de arquivos utilizados em sistemas operacionais, incluindo aqueles usados no Linux. Abaixo, vou citar e descrever alguns dos principais sistemas de arquivos existentes:
2.1 Ext4 (Quarta Versão Extendida):
O Ext4 é um sistema de arquivos amplamente utilizado no Linux. Ele é uma evolução do Ext3, projetado para melhorar o desempenho e a escalabilidade. O Ext4 oferece recursos avançados, como alocação de blocos aprimorada, suporte a tamanhos de arquivo e sistema de arquivos maiores, suporte a extensões (usado para armazenar atributos estendidos), entre outros. É comumente usado para sistemas Linux desktop e servidores.
2.2 Btrfs (B-tree File System):
O Btrfs é um sistema de arquivos moderno que oferece recursos avançados de gerenciamento de dados, como snapshots (pontos de restauração instantâneos), compressão, clonagem de subvolumes e RAID nativo. Ele foi projetado para ser uma alternativa ao Ext4 e oferece maior flexibilidade e confiabilidade em comparação com sistemas de arquivos mais antigos. O Btrfs é especialmente útil para cenários que envolvem grandes quantidades de dados ou armazenamento distribuído.
2.3 XFS (X File System):
O XFS é um sistema de arquivos de alto desempenho e dimensionável, ideal para ambientes que exigem grande capacidade de armazenamento e alto rendimento. Ele suporta arquivos grandes, metadados otimizados e recuperação rápida após falhas. O XFS é frequentemente usado em servidores de banco de dados, servidores de arquivos e outros cenários de armazenamento intensivo.
2.4 ZFS (Zettabyte File System):
Embora não seja nativo do kernel Linux, o ZFS é notável por suas capacidades avançadas de gerenciamento de armazenamento. Ele oferece snapshots eficientes, suporte a RAID, compactação, deduplicação (eliminação de dados duplicados) e muito mais. O ZFS é frequentemente usado em sistemas de armazenamento de grande escala e em ambientes onde a integridade e a segurança dos dados são críticas.
2.5 NTFS (New Technology File System):
Embora seja um sistema de arquivos associado ao Windows, o Linux também oferece suporte de leitura e gravação ao NTFS. Isso permite que você acesse e compartilhe arquivos em partições NTFS a partir de um sistema Linux.
2.6 FAT32 (File Allocation Table 32):
O sistema de arquivos FAT32 é amplamente compatível, mas tem limitações em relação ao tamanho máximo do arquivo e tamanho da partição. Ele é frequentemente usado em dispositivos USB, cartões SD e outros dispositivos de armazenamento portáteis.
2.7 HFS+ (Hierarchical File System Plus):
O HFS+ é um sistema de arquivos usado em sistemas operacionais macOS. Embora o suporte seja limitado no Linux, ferramentas e drivers estão disponíveis para acessar partições HFS+.
IMPORTANTE: cada sistema de arquivos possui suas próprias vantagens e desvantagens, e a escolha depende das necessidades específicas de armazenamento, desempenho e confiabilidade do seu sistema. É importante escolher o sistema de arquivos adequado para cada caso, levando em consideração os requisitos e os recursos disponíveis.
3. ESTRUTURA DE DIRETÓRIOS no Linux
O sistema de arquivos é uma parte fundamental do ecossistema Linux, fornecendo a estrutura necessária para armazenar, organizar e gerenciar dados. Vamos explorar agora a anatomia dos sistemas de arquivos no Linux, examinar a função de diretórios-chave e fornecer exemplos práticos para entender como eles trabalham juntos para formar uma experiência coesa no sistema operacional.
O Que é um Sistema de Arquivos no Linux?
Em termos simples, um sistema de arquivos é uma estrutura que permite ao sistema operacional armazenar, organizar e acessar dados em dispositivos de armazenamento, como discos rígidos, SSDs e pendrives. No Linux, os sistemas de arquivos são compostos por vários diretórios e arquivos, cada um desempenhando um papel específico na hierarquia do sistema.
Diretórios Fundamentais e Suas Funções
/ (Raiz)
O diretório raiz é o ponto de partida para a hierarquia do sistema de arquivos no Linux. Ele contém todos os outros diretórios e subdiretórios. Por exemplo, /bin e o /etc são subdiretórios do diretório raiz.
/bin
O diretório /bin contém os comandos essenciais do sistema, que são necessários para o funcionamento básico do sistema, mesmo durante a inicialização.
Exemplo: O comando “ls” utilizado para listar arquivos e diretórios, está localizado em “/bin”.
/etc
O diretório “/etc” armazena arquivos de configuração do sistema. Aqui, você encontrará configurações para vários aplicativos e serviços.
Exemplo: O arquivo “/etc/network/interfaces” define as configurações de rede do sistema.
/home
Cada usuário do sistema tem um diretório pessoal dentro de `/home`. Aqui, eles podem armazenar seus arquivos pessoais, documentos e configurações.
Exemplo: Se o nome de usuário for “joao”, o diretório pessoal dele será “/home/joao”.
/usr
O diretório “/usr” contém programas e arquivos acessíveis a todos os usuários do sistema. Ele é frequentemente usado para armazenar aplicativos e bibliotecas.
Exemplo: Os programas instalados via gerenciador de pacotes são armazenados em subdiretórios de “/usr”.
/var
O diretório /var é usado para armazenar dados variáveis, como arquivos de log, spools de impressão e arquivos temporários.
Exemplo: Os registros de eventos do sistema são armazenados em “/var/log”.
/tmp
O diretório “/tmp” é usado para armazenar arquivos temporários que são criados durante a execução do sistema.
Exemplo: Arquivos temporários gerados por aplicativos durante a execução são frequentemente armazenados em “/tmp”.
/dev
O diretório “/dev” contém arquivos especiais que representam dispositivos de hardware no sistema.
Exemplo: O dispositivo de som pode ser representado como “/dev/sound”.
/boot
O diretório “/boot” contém arquivos relacionados ao processo de inicialização do sistema, como o carregador de inicialização e os núcleos do sistema.
Exemplo: Os arquivos de configuração do carregador de inicialização GRUB estão em /boot/grub.
Figura 1: Estrutura de Diretórios no Linux
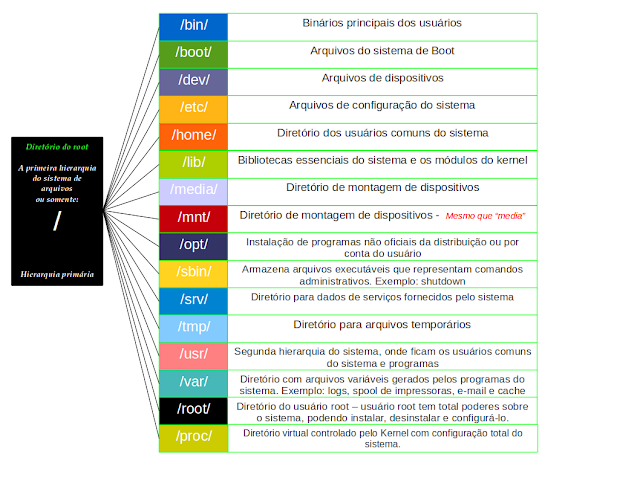
Fonte: https://linuxeprogramacao.blogspot.com/2013/07/organizacao-dos-diretorios-linux.html
Importante:
O entendimento dos sistemas de arquivos e a função de cada diretório são essenciais para navegar e administrar com eficiência um sistema Linux. A hierarquia cuidadosamente projetada desses diretórios permite que você organize seus arquivos, ajuste configurações do sistema e realize tarefas diversas. Ao explorar os diversos diretórios e exemplos fornecidos neste guia, você estará bem equipado para aproveitar ao máximo o poder do Linux em seu ambiente de Tecnologia da Informação.
Lembre-se de que este é apenas um vislumbre da complexidade e riqueza dos sistemas de arquivos e diretórios no Linux. Ao aprofundar seu conhecimento e explorar ainda mais, você descobrirá um mundo de possibilidades para personalizar, otimizar e dominar o sistema operacional Linux.
4. Principais Comandos para Gerenciamento de Arquivos e Diretórios no Linux
O Linux oferece um conjunto poderoso de comandos para gerenciamento de arquivos e diretórios, permitindo que você navegue, organize e manipule seus dados de forma eficiente. Exploraremos abaixo alguns comandos essenciais para o gerenciamento de arquivos e diretórios no Linux, fornecendo exemplos práticos para ilustrar como usá-los no dia a dia.
Comando 1: ls – Listar Arquivos e Diretórios
O comando “ls” é usado para listar os arquivos e diretórios em um diretório específico.
Exemplos Práticos:
1. Listar todos os arquivos e diretórios no diretório atual:
ls
2. Listar arquivos detalhadamente, incluindo permissões, proprietário e data de modificação:
ls -l
3. Listar arquivos ocultos (começando com ponto) no diretório atual:
ls -a
4. Listar arquivos e diretórios em formato de lista longa e com tamanhos em formato legível pelo usuário:
ls -lh
5. Listar apenas diretórios no diretório atual:
ls -d */
Comando 2: cd – Mudar de Diretório
O comando “cd” é usado para mudar de diretório.
Exemplos Práticos:
1. Navegar para um diretório específico:
cd /caminho/do/diretorio
2. Navegar para o diretório pessoal do usuário:
cd ~
3. Navegar para o diretório pai:
cd ..
4. Voltar para o diretório anterior:
cd -
5. Navegar para um diretório usando atalhos:
cd / # Vai para a raiz
cd .. # Vai para o diretório pai
cd ~/Documentos # Vai para o diretório "Documentos" no diretório pessoal
Comando 3: cp – Copiar Arquivos e Diretórios
O comando “cp” é usado para copiar arquivos e diretórios.
Exemplos Práticos:
1. Copiar um arquivo para um diretório específico:
cp arquivo.txt /caminho/do/diretorio
2. Copiar um arquivo mantendo o mesmo nome em um diretório diferente:
cp arquivo.txt /caminho/do/novo/diretorio/
3. Copiar um diretório inteiro e seu conteúdo para outro diretório:
cp -r diretorio_origem/ diretorio_destino/
4. Copiar todos os arquivos de uma extensão específica para um diretório:
cp *.txt /caminho/do/diretorio
5. Copiar interativamente, perguntando antes de sobrescrever arquivos existentes:
cp -i arquivo.txt /caminho/do/diretorio
Comando 4: mv – Mover ou Renomear Arquivos e Diretórios
O comando “mv” é usado para mover ou renomear arquivos e diretórios.
Exemplos Práticos:
1. Mover um arquivo para um diretório específico:
mv arquivo.txt /caminho/do/diretorio
2. Renomear um arquivo:
mv arquivo_antigo.txt arquivo_novo.txt
3. Mover um diretório inteiro e seu conteúdo para outro diretório:
mv diretorio_origem/ diretorio_destino/
4. Mover arquivos de uma extensão específica para um diretório:
mv *.pdf /caminho/do/diretorio
5. Mover e renomear interativamente:
mv -i arquivo.txt /caminho/do/novo/diretorio/novo_nome.txt
Comando 5: rm – Remover Arquivos e Diretórios
O comando “rm” é usado para remover arquivos e diretórios.
Exemplos Práticos:
1. Remover um arquivo:
rm arquivo.txt
2. Remover um diretório vazio:
rm -d diretorio_vazio/
3. Remover um diretório e seu conteúdo recursivamente (cuidado ao usar este comando):
rm -r diretorio_com_conteudo/
4. Remover um arquivo sem confirmação (tenha cuidado):
rm -f arquivo.txt
5. Remover interativamente, solicitando confirmação antes de cada remoção:
rm -i arquivo.txt
Importante
Dominar esses comandos essenciais de gerenciamento de arquivos e diretórios no Linux Ubuntu permitirá que você navegue e organize seus dados de maneira eficaz. Lembrando sempre de tomar cuidado ao usar comandos de remoção para evitar perda de dados acidental. À medida que você pratica esses comandos e explora suas opções, você se tornará mais proficientes em administrar seus arquivos e diretórios no ambiente Linux.
5. Dominando Metacaracteres e Operadores no Linux
Os metacaracteres e operadores desempenham um papel fundamental na potencialização da linha de comando no Linux Ubuntu. Essas ferramentas avançadas permitem que você execute tarefas complexas, filtre dados e encadeie comandos de maneira eficaz, confira.
Metacaractere * (Asterisco) – Combinar Qualquer Caractere
O metacaractere * representa qualquer sequência de caracteres (incluindo nenhum).
Exemplos Práticos:
1. Listar todos os arquivos .txt em um diretório:
ls *.txt
2. Mover todos os arquivos com extensão `.jpg` para um diretório de imagens:
mv *.jpg /caminho/do/diretorio
3. Apagar todos os arquivos de backup no diretório:
rm *~
4. Pesquisar por um padrão em arquivos de log:
grep "erro*" arquivo.log
5. Contar quantos arquivos .pdf estão em um diretório:
ls *.pdf | wc -l
Operador “>” (Redirecionamento de Saída)
O operador “>” redireciona a saída de um comando para um arquivo, substituindo o conteúdo do arquivo se ele existir.
Exemplos Práticos:
1. Salvar a lista de arquivos em um diretório em um arquivo de texto:
ls > lista_arquivos.txt
2. Criar um novo arquivo ou sobrescrever um arquivo existente:
echo "Texto de exemplo" > arquivo.txt
3. Redirecionar a saída de um comando para um arquivo de log:
comando_executado > saida.log
4. Substituir o conteúdo de um arquivo com a saída de um comando:
echo "Novo conteúdo" > arquivo_existente.txt
5. Redirecionar a saída de erro padrão para um arquivo:
comando_desconhecido_2 > erro.log
Operador “>>” (Redirecionamento de Saída, Modo Anexar)
O operador “>>” redireciona a saída de um comando para um arquivo, anexando ao conteúdo existente.
Exemplos Práticos:
1. Adicionar informações de log ao final de um arquivo de registro:
echo "Novo log" >> log.txt
2. Anexar resultados de um comando de listagem ao arquivo de diretórios:“`
ls >> diretorios.txt
3. Adicionar saída de erro padrão a um arquivo existente:
comando_desconhecido_2 >> erro.log
4. Manter um registro contínuo de eventos em um arquivo de histórico:
echo "$(date): Evento ocorrido" >> historico.log
5. Registrar saída de um comando e saída de erro em um arquivo:
comando_com_erro >> saida.log_2 > &1
Operador “|” (Pipe)
O operador “|” permite encadear a saída de um comando como entrada para outro comando, permitindo processamento sequencial.
Exemplos Práticos:
1. Contar quantas vezes uma palavra aparece em um arquivo de texto:
cat arquivo.txt | grep -c "palavra"
2. Listar todos os arquivos no diretório ordenados alfabeticamente:
ls | sort
3. Filtrar linhas contendo um padrão específico e ordenar o resultado:
cat log.txt | grep "erro" | sort
4. Contar a quantidade de linhas em um arquivo usando `wc`:
cat arquivo.txt | wc -l
5. Analisar a saída de um comando com `awk` para exibir informações específicas:
comando_complexo | awk '{print $1, $3}'
Metacaractere ? (Interrogação) – Combinar um Caractere Qualquer
O metacaractere ? representa qualquer caractere único.
Exemplos Práticos:
1. Encontrar arquivos com nomes de exatamente três caracteres:
ls ???
2. Listar arquivos com extensão de três letras:
ls *.???
3. Procurar por um caractere específico em nomes de arquivo:
ls ?le.txt
4. Contar a quantidade de arquivos com nomes de três letras:
ls ??? | wc -l
5. Filtrar linhas com um caractere específico em um arquivo de texto:
cat arquivo.txt | grep 'p?dr?o'
Importante
Os metacaracteres e operadores do Linux Ubuntu oferecem um poderoso conjunto de ferramentas para manipular dados, processar informações e encadear comandos. Ao dominar essas funcionalidades, você se tornará mais eficiente na execução de tarefas complexas e no gerenciamento de informações em seu sistema. Lembre-se de praticar esses exemplos e explorar novas maneiras de combinar metacaracteres e operadores para se tornar um mestre na linha de comando do Linux.
6. Dominando a Busca de Arquivos e Diretórios no Linux Ubuntu: Comandos Essenciais
Localizar arquivos e diretórios é uma tarefa essencial na administração de sistemas Linux Ubuntu. Felizmente, existem vários comandos poderosos que facilitam essa tarefa. Neste artigo, vamos explorar cinco dos principais comandos para localizar arquivos e diretórios no Linux Ubuntu, fornecendo exemplos práticos para mostrar como utilizá-los efetivamente.
Comando 1: find – Localizar Arquivos e Diretórios
O comando find é uma ferramenta versátil para localizar arquivos e diretórios com base em vários critérios, como nome, tipo, tamanho e muito mais.
Exemplos Práticos:
1. Localizar todos os arquivos com uma determinada extensão no diretório atual:
find . -name "*.txt"
2. Encontrar diretórios vazios no sistema:
find / -type d -empty
3. Procurar por arquivos modificados nas últimas 24 horas:
find /home -mtime -1
4. Localizar arquivos executáveis em todo o sistema:
`
find / -type f -executable
5. Buscar por arquivos com permissões específicas:
find / -type f -perm 644
Comando 2: locate – Localizar Arquivos Rapidamente
O comando locate é uma maneira rápida de encontrar arquivos, pois utiliza um banco de dados pré-construído.
Exemplos Práticos:
1. Atualizar o banco de dados de pesquisa (execute antes de usar locate):
sudo updatedb
2. Localizar todos os arquivos contendo a palavra “ubuntu” no nome:
locate ubuntu
3. Encontrar todos os arquivos com a extensão .conf:
locate *.conf
4. Buscar por um arquivo específico usando uma correspondência exata:
locate -b '\arquivo.txt'
5. Localizar arquivos de log no diretório `/var`:
locate /var/*.log
Comando 3: grep – Pesquisar Conteúdo de Arquivos
O comando grep é usado para pesquisar texto em arquivos.
Exemplos Práticos:
1. Pesquisar uma palavra-chave em todos os arquivos de texto:
grep "palavra" *.txt
2. Encontrar todas as ocorrências de uma expressão em um diretório:
grep -r "expressão" /caminho/do/diretório
3. Pesquisar uma palavra em arquivos ignorando maiúsculas e minúsculas:
grep -i "exemplo" arquivo.txt
4. Exibir o número da linha junto com a correspondência:
grep -n "linha" arquivo.txt
5. Procurar por um padrão com várias palavras no arquivo:
grep "palavra1\|palavra2" arquivo.txt
Comando 4: which – Encontrar o Caminho de Executáveis
O comando which é usado para localizar o caminho de um executável.
Exemplos Práticos:
1. Encontrar o caminho para o comando ls:
which ls
2. Verificar o local do executável python:
which python
3. Localizar o caminho para o comando grep:
which grep
4. Encontrar o diretório onde o comando está localizado:
which -a comando
5. Verificar o caminho de um programa específico:
which programa
Comando 5: updatedb – Atualizar Banco de Dados do locate
O comando updatedb é usado para atualizar o banco de dados usado pelo comando locate.
Exemplos Práticos:
1. Atualizar o banco de dados de pesquisa manualmente:
sudo updatedb
2. Agendar uma atualização periódica do banco de dados (geralmente em cron jobs):
sudo nano /etc/updatedb.conf
3. Verificar a última vez que o banco de dados foi atualizado:
ls -l /var/lib/mlocate/mlocate.db
4. Personalizar as opções de atualização do banco de dados (consulte a documentação):
man updatedb
5. Verificar o status do serviço de atualização de banco de dados:
systemctl status updatedb
Conclusão
Ao longo deste artigo abrangente, exploramos os fundamentos e as funcionalidades dos comandos GNU e Unix no Linux. Desde o sistema de arquivos e a estrutura de diretórios, a navegação e gerenciamento de arquivos até o uso de metacaracteres, operadores e ferramentas avançadas de busca e compactação, você adquiriu um conjunto de habilidades poderosas para aproveitar ao máximo o ambiente Linux.
À medida que você continua a explorar e praticar esses comandos, estará bem amparado para enfrentar os desafios da administração de sistemas e expandir suas capacidades na área de Tecnologia da Informação. Parabéns por se aprofundar nesse mundo fascinante da linha de comando Linux!